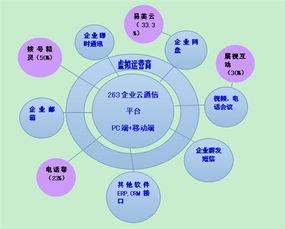
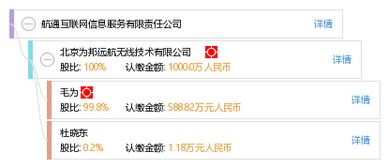
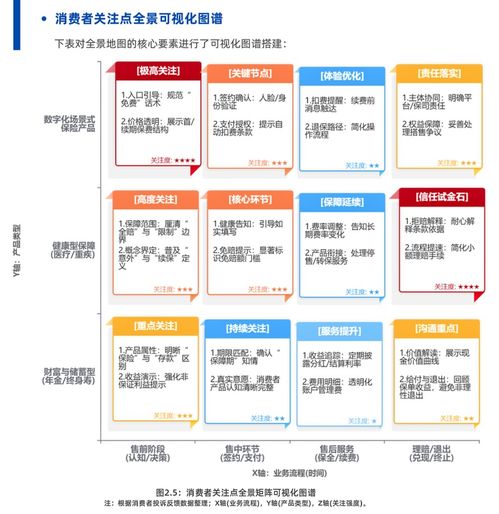
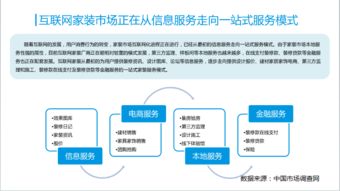
北京新華國信科貿有限責任公司 專注互聯網信息服務業務

北京新華國信科貿有限責任公司是一家致力于提供專業互聯網信息服務的企業,其核心業務聚焦于互聯網信息服務領域。公司依托先進的技術平臺和豐富的行業經驗,為客戶提供高效、安全、可靠的信息服務解決方案。在數字化時代背景下,該公司通過優化信息處理流程、保障數據安全與合規性,助力企業和個人用戶實現信息資源的有效整合與價值提升。北京新華國信科貿有限責任公司將繼續深化技術創新,拓展服務范圍,推動互聯網信息服務行業的可持續發展。
如若轉載,請注明出處:http://m.yaozer.cn/product/12.html
更新時間:2026-06-19 05:30:15